In Produktdatenblättern so gut wie aller Storage-Anbieter taucht im Zusammenhang mit Storage-Management immer öfter der Begriff Erasure Coding (EC) auf. Insbesondere All-Flash-Arrays bieten kein RAID mehr an. Für SSDs eignet sich Erasure Coding sehr viel besser als herkömmliches RAID-5 oder RAID-6. Wir erklären im Artikel Grundbegriffe des Erasure Codings, erläutern die prinzipielle Funktion und gehen auf Vor- und Nachteile des Erasure Codings ein.
Motiviert ist Erasure Coding durch zwei markante Entwicklungen in der Enterprise-IT. Mit zunehmender Kapazität der Festplatten dauert der Rebuild eines defekten RAIDs immer länger. Es braucht etwa 20 Stunden, um eine aktuelle 16TB-Platte einmal komplett neu zu beschreiben. Um durch das RAID-Rebuild das produktive I/O nicht zu stören, laufen diese Rebuilds in der Regel mit geringer Priorität im Hintergrund. Das erhöht die Wiederherstellungszeit entsprechend. Rebuild-Zeiten von 1-2 Tagen sind mittlerweile keine Seltenheit mehr. Darüber hinaus bedeutet aufgrund der Funktion von RAID-5 oder RAID-6 der Rebuild einer einzelnen Platte auch viel mechanischen Stress für alle Platten im RAID-Verbund. Es kommt durchaus vor, dass während eines Rebuilds weitere Platten ausfallen. In Umgebungen mit vielen Festplatten geht man deshalb häufig weg von RAID-6 hin zu Mehrfach-Replikation. Das komplette Dataset ist also mehrfach redundant (häufig 3-fach) abgelegt. Das benötigt entsprechend viele Speichermedien und erschwert das Dateimanagement.
Eine weitere Herausforderung ist die zunehmende Verbreitung virtueller Umgebungen sowie von Hyper-Converged-Infrastructure (HCI). Dateisysteme spannen sich nicht mehr nur über Festplatten bzw. SSDs innerhalb eines Systems. Verteilte Dateisysteme bieten einen einheitlichen Namespace über mehrere Systeme. Damit ist es sehr einfach möglich, z. B. eine virtuelle Maschine auf einem beliebigen Host innerhalb der HCI zu starten. RAID funktioniert nur innerhalb eines Systems. Mit Erasure Coding kann diese Begrenzung aufgehoben werden.
Erasure Coding. Was ist das?
Erasure Coding gehört in den Bereich der sogenannten fehlerkorrigierenden Codes, manchmal auch als Forward Error Correction (FEC) bezeichnet. Den wissenschaftlichen Hintergrund hat Erasure Coding im mathematischen Fachgebiet der linearen Algebra. Intensiv erforscht werden diese Codes seit ca. den 1960er Jahren. Bereits früh wurden solche Codes für die digitale Datenübertragung über Weitverkehrsstrecken genutzt. Erasure Coding bei Datenträgern wurde erstmals 1982 kommerziell mit der Markteinführung von Audio-CDs genutzt. Erasure Codes werden auch auf DVDs und für DVB-S genutzt.
Der bekannteste Algorithmus ist der Reed-Solomon-Algorithmus, benannt nach den beiden Erfindern (beides Mathematiker). Es gibt daneben noch eine Reihe weiterer Algorithmen mit verschiedenen Vor- und Nachteilen. Die Forschung ist noch lange nicht abgeschlossen, mit der intensiven Verwendung von Erasure Coding ergeben sich neue Frage- und Problemstellungen, die es lohnt, im Detail zu betrachten.
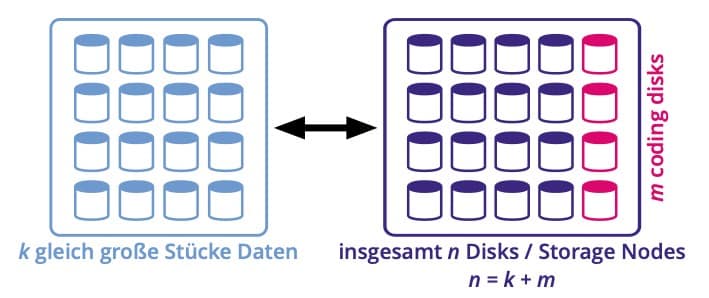
Das Grundprinzip dieser Codes ist jedoch immer das selbe: Daten, die in ein System hinein gelangen, werden in eine festgelegte Anzahl gleich großer Brocken (Daten-Chunks) aufgeteilt. Anschließend werden diese Chunks nach mathematischen Verfahren um Redundanzinformation ergänzt (Redundanz-Chunks). Schließlich werden Daten-Chunks und Redundanz-Chunks auf ein Speichermedium abgelegt. Dabei können für Redundanz-Chunks eigene Platten vorgesehen sein (horizontale Codes) oder die Redundanz Information wird zusammen mit Daten-Chunks auf dieselben Platten geschrieben (vertikale Codes). Letzteres ist die weitaus häufigere Methode.
Terminologie und Notation
Eine typische Notation für Erasure Coding wäre so etwas wie EC(20,16) oder EC(12,9). Mathematisch und allgemeingültig ausgedrückt ist das EC(n,k). Dabei ist n die Anzahl der gesamten Festplatten in einem System, k ist die Anzahl der Datenplatten. Die Differenz n–k ist die Anzahl der für Redundanz benutzten Platten. Das ist zugleich auch die Anzahl an Festplatten, die in einem solchen Verbund ausfallen dürfen, ohne dass die Datenintegrität verletzt wird. In der Praxis sieht man auch immer häufiger die sehr viel leichter verständliche Bezeichnung Erasure Coding 9+3. In diesem Beispiel ist Erasure Coding 9+3 identisch zu EC(12,9). Insgesamt drehen sich in diesem Verbund 12 Platten, 3 davon dürfen ausfallen, ohne dass Daten verloren gehen.
Das Verhältnis Daten- zu Redundanz-Chunks lässt sich abhängig vom verwendeten Algorithmus in Grenzen individuell einstellen. Das Verhältnis hat Auswirkung auf Performance, auf die Anzahl Platten, die ausfallen dürfen, sowie auf erforderliche CPU- und Netzwerkleistung im Recovery-Fall. In der Praxis kann bzw. muss der Storage-Admin selten das Verhältnis individuell festlegen. Hersteller bieten in der Management-Oberfläche i. d. R. mehrere vorkonfigurierte Erasure Codings. Der Administrator wählt dann nur noch zwischen Optimierung auf Geschwindigkeit, Optimierung auf Kapazität oder Optimierung auf Zuverlässigkeit und überlässt der Firmware, das jeweils passende Erasure Coding auszuwählen.
Vorteile des Erasure Coding
Erasure Coding kann mehr und flexiblere Redundanz bieten als RAID-5 und RAID-6. Das haben wir bereits kurz umrissen. Neben den technischen Vorteilen ist bei Erasure Coding i. d. R. auch die Beschaffung der Hardware deutlich günstiger, weil im Vergleich zu RAID für gleiche oder bessere Redundanz deutlich weniger Festplatten benötigt werden.
Ein Rechenbeispiel:
Wir nehmen an, ein Storage-System bietet ein Erasure Coding EC(12,9) bzw. 9+3. In einem Setup mit insgesamt 12 Festplatten können also 3 Platten ausfallen, und die Datenintegrität ist noch immer gegeben. Mit herkömmlichem RAID ist diese Redundanz nicht möglich. Um eine Redundanz größer zwei Platten zu erhalten, würde man dort z. B. auf ein RAID-5 mit drei Replikas zurückgreifen. Wir nehmen weiter an, dass wir moderne 16TB-Festplatten benutzen. Diese Platten kosten derzeit (September 2020) etwa 400€ je Stück. Das EC(12,9) hat neun Datenplatten, also 9 x 16TB = 144 TB nutzbar für Dateisystem. Insgesamt müssen 12 Platten beschafft werden, also 12 x 400€ = 4.800€.
Sehr anders sieht die Rechnung mit gleicher Nutzkapazität aber dreifacher Replikation eines RAID-5 aus. Für 144 TB Nutzkapazität braucht man auch hier 9 Disks. Zusätzlich eine zehnte Platte für die Redundanz in einem RAID-5. Weil wir aber dreifach redundant schreiben, braucht man schließlich 3 x 10 Disks = 30 Disks. Mit den gleichen 16TB-Platten wie oben kommt man hier also auf 30 x 400€ = 12.000€ Beschaffungskosten. RAID-5 mit Replikation ist in diesem Beispiel also zweieinhalb mal so teuer in der Anschaffung, wie ein gleich redundantes System auf Basis Erasure Coding.
Weitere Einsparungen ergeben sich durch den geringeren Platzbedarf (Volumen und Stellfläche) im Rechenzentrum (12 Disks vs. 30 Disks). Damit einhergehend sinken auch Stromverbrauch und Klimaleistung im Serverraum. Letzteres spielt zugegeben nur eine marginale Rolle bei der TCO-Betrachtung im Gesamtbetrieb.
Jede Medaille hat zwei Seiten
Fällt eine Platte oder ein Storage Node aus, müssen Daten rekonstruiert werden. Dazu werden verschiedene noch intakte Daten-Chunks sowie intakte Redundanz-Chunks gelesen und daraus gemäß Erasure-Coding-Algorithmus die fehlenden Daten errechnet. Die Wiederherstellung ist bei Erasure Coding etwas rechenintensiver als das bei herkömmlichem RAID der Fall ist. Abhängig vom Algorithmus kann die Wiederherstellung insbesondere I/O-intensiv sein, weil u. U. viele Chunks gelesen werden müssen. Bei verteilten Dateisystemen muss dieser Umstand bei der Dimensionierung der Netzwerkverbindungen berücksichtigt werden.
Neuere Implementierungen im Bereich HCI und verteilte Dateisysteme benutzten sogenannte Locally Repairable Codes (LRC). Redundanz wird dabei so angelegt und verteilt, dass z. B. der Ausfall einer einzelnen Platte innerhalb eines Storage-Nodes auch innerhalb des betroffenen Storage-Nodes wieder rekonstruieren lässt. Es entsteht also kein zusätzlicher Netzwerk-Traffic im Restore-Fall. Erst bei Ausfall mehrerer Platten oder eines kompletten Storage-Nodes müssen auch Chunks aus benachbarten Nodes gelesen werden.
Bei einem RAID-Rebuild wird eine ausgefallene und ersetzte Festplatte blockweise identisch beschrieben mit Status vor dem Ausfall. Bei Erasure Coding wird die Redundanz Information in einem System verteilt abgelegt. Beim Rebuild können die durch einen Plattenausfall fehlenden Daten- und Redundanz-Chunks neu berechnet und auf die verbliebenen Platten im System geschrieben werden. Damit ist die I/O-Leistung einer einzelnen Festplatte nicht mehr der Flaschenhals beim Rebuild, wie das bei RAID der Fall ist.
Viele Enterprise-Storage-Systeme nutzen mittlerweile Erasure Coding. Auch sämtliche Cloudanbieter setzen bei ihren Storage-Produkten auf Erasure Coding. Wir bei Cristie Data setzen Erasure Coding ebenfalls ein, u. a. bei unseren CLOUDBRIK-Angeboten.